Linux-0.11 源码解析与思考题
拟题 杨力祥老师
初稿 李效宇同学
整理&终稿 李辰剑 2022-12-31
写在前面
写作背景
这篇笔记来源于这学期的操作系统课程。课程上,杨老师带同学们一起手撕早期版本的 Linux 源代码,非常刺激。
杨老师在期末前出了很多思考题,供同学们参考、复习。李效宇同学则花了不少功夫,结合上课内容和网上资料,整理了所有思考题的答案,分享给同学。
李效宇同学的原文链接:https://lixiexie.notion.site/dbfc366cee8f4931bfa33d414b1132f9
我看到了这篇长文之后觉得内容很棒,便决定转载到自己的博客上。于是我对内容进行了全面的修订,最终得到了这篇文章。
修订内容
本以为只是修改一些错别字和优化排版,没有想到最后却成为了大工程,花费了我小半个学期。对文本的修订和优化包括:
- 修订了一些错别字、并对文字进行了润色,让文字更书面化。
- 对代码使用了程序环境进行排版,优化了总体排版。
- 修改了一些错误答案,例如“25. 为什么
static inline _syscall0(type,name)中需要加上关键字inline?”——实际原因不是优化性能,而是与写时复制 (CoW, Copy on Write) 机制有关。 - 重写/扩充了一些问题的答案。
- 对思考题顺序进行了调整,让问题之间的逻辑更紧密连贯。想按寻找某道特定思考题答案的同学,可以参考文末附录:「思考题调整前后编号对照表」。
- 将许多图片替换为了高清版本,增加了一些示意图。
- 添加了参考文献。
阅读指南
文中有许多内容是对 Linux-0.11 源代码的解析,还有一部分是对 Intel IA-32 体系结构的分析。对于没有阅读过 Linux 源代码的读者来说可能有些难懂。我建议读者的阅读方法有如下几种:
- 对计算机感兴趣但不熟悉 Linux 源码也不愿意花费太多时间的读者,可以不求甚解地阅读。文中有一些 IA-32 体系结构相关的内容,也许能拓宽你的知识面,帮助你理解计算机体系结构。文中有一些关于 Linux 操作系统设计思路的内容,也许能向你展现操作系统的具体实现,帮你把抽象的操作系统概念落到具体的实现上。
- 了解 Linux 源码,或者准备认真研读的读者,可以配合文末给出的参考资料(即参考文献)阅读。赵炯博士的《Linux内核完全注释》是一本功力极为深厚的 Linux 源码解析专著,我强力推荐。杨力祥老师的《Linux内核设计的艺术》则与文中的思考题思路最为契合。最后,解析 Linux 源码最少不了的便是 Linux 源码本身和 Intel IA-32 芯片手册——后者是当时乃至当今绝大多数操作系统的体系结构基础。源码和《完全注释》可以在 www.oldlinux.org 获得,其余资料也大都可以从网上获得。如果你想偷懒,也可以向我发邮件要资料。我的邮箱是 icy_chlorine@pku.edu.cn。
- 对于正在上/上过杨老师操作系统课的同学,你阅读整篇文章应该没有太大的障碍。根据杨老师上课的思路或者《Linux内核设计的艺术》书中的思路走即可。
记号约定:
寄存器用带百分号的代码环境表示,如
%eip,%eax。函数、变量、标识符、内存地址用程序环境排版,如
main(),dir,0x7c00。- 体系结构中的专有概念(如全局描述符表 GDT、基本输入输出系统 BIOS)用一般环境排版。
- Linus 时代多使用 8 空格长的 tab 缩进,而如今的编辑器大都默认使用 4 个空格缩进,并将 tab 页渲染为四个空格长的空白。为了让代码和注释能正常对齐,将代码中的缩进全部替换为了与当时等长的空格。
- 引用代码中,用 C++ style 注释(
//...)表示我们添加的注解,以和 Linux 源代码中的 C style 注释(/*...*/)区分。
Part I 启动与 Intel IA-32 体系结构
1. 为什么开始启动计算机的时候,执行的是 BIOS 代码而不是操作系统自身的代码?
计算机只能从内存中运行程序,而无法直接从软盘或者硬盘中运行程序。不幸的是,计算机刚启动的时候,内存中空空如也、没有任何程序,需要将程序本身先加载进内存当中。这部分操作就由 BIOS(Basic Input/Output System) 完成。加电后, BIOS 完成一些硬件检测工作,设置实模式下的中断向量表和服务程序,并将操作系统的引导扇区加载至内存地址 0x7C00 处,然后将跳转至 0x7C00 运行操作系统的代码。
“实模式”是对 Intel x86 体系结构而言的
BIOS 程序存放在只读存储器 ROM(Read Only Memory) 中。ROM 断电后也能保持信息,但不能改变数据(或修改数据很困难),适合存放 BIOS 这种不需要修改的例行工作。通过内存映射,可以让处理器在上电后最先执行 ROM 中的程序,所以计算机启动最开始运行的是 BIOS 代码。BIOS 在计算机上电启动和操作系统代码之间增加了一层 indirection,使得同样的硬件上可以运行不同的操作系统。
2. 为什么 BIOS 只加载了一个扇区,后续扇区却是由 bootsect 代码加载?为什么 BIOS 没有直接把所有需要加载的扇区都加载?
bootsect,setup,head指bootsect.s,setup.s,head.s编译以后形成的二进制可执行文件。
BIOS 和操作系统的通常由不同团队开发,按固定的规则约定,可以灵活的设计各自相应的部分。而“BIOS 运行后,只从启动扇区将代码加载至 0x7c00 位置”,便是 BIOS 和操作系统之间相互接洽的约定。以 Linux0.11 为例,后续的扇区由 bootsect 代码加载,这些代码由编写系统的用户负责,与 BIOS 无关。
这样构建的好处是站在整个体系的高度,统一设计和统一安排,简单而有效。BIOS 和操作系统的开发都可以遵循这一约定,灵活地进行各自的设计。例如,BIOS 可以不用知道内核镜像的大小以及其在软盘的分布等等信息,减小了 BIOS 程序的复杂度,降低了硬件上的开销。而操作系统的开发者也可以按照自己的意愿,内存的规划等等都更为灵活。另外,如果要使用 BIOS 进行加载,而且加载完成之后再执行,则需要很长的时间,此外,对于不同的操作系统,其代码长度不一样,可能导致操作系统加载不完全。因此 Linux 采用的是边执行边加载的方法。
3. 为什么 BIOS 把 bootsect 加载到 0x07c00,而不是 0x00000?加载后又马上挪到 0x90000 处,是何道理?为什么不一次加载到位?
若未加说明,十六进制地址默认为内存中地址。
加载到
0x07c00是 BIOS 提前约定设置的。- BIOS 把
bootsect.s加载到0x07c00而不是0x00000,是因为0x00000处存放着 BIOS 构建的 1k 大小的中断向量表和 256B 的 BIOS 数据区,这些数据还有用处,不能覆盖。 - BIOS把
bootsect.s加载到0x07c00而不是内存高地址处,是因为早期的计算机(IBM兼容机)只有64KB 内存,高地址端为0x7fff。为了把尽量多的连续内存留给操作系统,BIOS 就将读取的数据放到了当时内存地址的尾部。随着计算机的发展,这一约定被保留了下来,于是 BIOS 便一直约定将引导扇区加载到0x7c00处[6]。
- BIOS 把
加载后又挪到
0x90000,是因为操作系统规划在内存0x90000处存放bootsect,然后bootsect执行结束之后,立即将系统机器数据存放在此处,这样就可以及时回收寿命结束的程序占据的内存空间。而且后续会把120K的系统模块存放到0x00000处,这会覆盖0x07c00处的代码和数据。- 不一次加载到位的原因是由于“两头约定”和“定位识别”,所以在开始时
bootsect“被迫”加载到0x07c00位置。随后将自身移至0x90000处,说明操作系统开始根据自己的需要安排内存了。
4. bootsect、setup、head程序之间是怎么衔接的?给出代码证据。
bootsect→setup程序:jmpi 0,SETUPSEGbootsect首先利用int 0x13中断分别加载setup程序及system模块,待bootsect程序的任务完成之后,执行代码jmpi 0,SETUPSEG。由于bootsect将setup段加载到了SETUPSEG:0(即0x90200),在实模式下,CS:IP 指向setup程序的第一条指令,此时setup开始执行。setup→head程序:jmpi 0,8执行
setup后,内核被移到了0x00000处,系统进入了保护模式,执行jmpi 0,8并加载了中断描述符表和全局描述符表
lidt idt_48; 1gdt gdt_48。在保护模式下,一个重要的特征就是根据 GDT 决定后续执行哪里的程序。该指令执行后跳转到以 GDT 第 2 项中的base_addr为基地址,以 0 为偏移量的位置,其中base_addr为0。由于head放置在内核的头部,因此程序跳转到head中执行。
5. setup 程序的最后是jmpi 0,8 ,为什么这个8不能简单的当作阿拉伯数字 8 看待,有什么内涵?
此时为 32 位保护模式,0 表示段内偏移,8 表示段选择符。这里8要转化为二进制:1000,最后两位00表示内核特权级(若是 11 则表示用户),第三位 0 表示 GDT 表(若是 1 则表示 LDT 表),第四位 1 表示根据 GDT 中的第2项来确定代码段的段基址和段限长等信息。可以得到代码是从 head 的开始位置,段基址 0x00000000、偏移为 0 处开始执行的,即 head 的开始位置。
6. 保护模式在“保护”什么?它的“保护”体现在哪里?特权级的目的和意义是什么?分页有“保护”作用吗?
保护模式在“保护”什么?它的“保护”体现在哪里?
保护操作系统的安全,不受到恶意攻击。保护进程地址空间相互不干扰。早期的操作系统没有指令集的保护,只是运行在计算机上的一个普通服务程序而已。应用程序甚至可以“干掉”操作系统,释放 OS 占用的内存,来满足自身的需求[7]。
打开保护模式后,CPU 的寻址模式发生了变化,基于全局描述符表 GDT 去获取代码或数据段的基址限长,不同段不能被随意访问。这防止了对代码或数据段的覆盖以及代码段自身的访问超限,明显增强了保护作用。保护模式下的处理器对描述符所描述的对象进行保护:在 GDT、 LDT 及 IDT 中,均有对应界限、特权级等概念,这是对描述符所描述的对象的保护。在不同特权级间访问时,系统会对 CPL、 RPL、 DPL、 IOPL 等进行检验,特权级不够的代码无法访问高权限的段。同时,处理器页会限制某些特殊指令如
lgdt,lidt,cli等的使用;分页机制中, PDE 和 PTE 中的R/W和U/S等位提供了页级保护,分页机制通过将线性地址与物理地址的映射,提供了对物理地址的保护。特权级的目的和意义是什么?
特权级机制目的是为了进行合理的管理资源,保护高特权级的段。其中操作系统的内核处于最高的特权级。
特权级机制对系统进行了保护,对操作系统的“主奴机制”影响深远。Intel 从硬件上禁止低特权级代码段使用部分关键性指令,例如禁止用户进程使用
cli、sti等对掌控局面至关重要的指令。这使得操作系统有可能真正成为计算机上超越用户进程的存在,而不仅仅是一个服务性程序。有了这些基础,操作系统可以把内核设计成最高特权级,把用户进程设计成最低特权级。这样,操作系统可以访问 GDT、 LDT、 TR,而 GDT、 LDT 是逻辑地址变换至线性地址的关键,因此操作系统可以掌控线性地址。物理地址是由内核将线性地址转换而成的,所以操作系统可以访问任何物理地址,而用户进程只能使用逻辑地址。总之,特权级的引入对操作系统内核进行保护。「分页」有“保护”作用吗?
分页机制有保护作用,使得用户进程不能直接访问内核地址,进程间也不能相互访问。用户进程只能使用逻辑地址,而逻辑地址通过内核转化为线性地址,根据内核提供的专门为进程设计的分页方案,由 MMU 直接映射转化为实际物理地址形成保护。此外,通过分页机制,每个进程都有自己的专属页表,有利于更安全、高效的使用内存,保护每个进程的地址空间。
事实上,在较新版本的 Linux 中,内存保护已经改由分页机制实现,不再使用段机制实现了。这是因为分页的控制更扁平化,更灵活,且在不同体系结构上的可移植性更好。
为什么特权级是基于段的?
在操作系统设计中,一个段一般实现的功能相对完整,可以把代码放在一个段,数据放在一个段,并通过段选择符(包括
CS、SS、DS、ES、FS和GS寄存器)获取段的基址和特权级等信息。通过段,系统划分了内核代码段、内核数据段、用户代码段和用户数据段等不同的数据段,有些段是系统专享的,有些是和用户程序共享的,因此就有特权级的概念。特权级基于段,这样当段选择子具有不匹配的特权级时,按照特权级规则评判是否可以访问。特权级基于段,是结合了程序的特点和硬件实现的一种考虑。
7. 打开 A20 和打开 PE 究竟是什么关系,保护模式不就是 32 位的吗?为什么还要打开 A20?有必要吗?
PE(Protection Enabled) 是 %eflags 中的重要一位,用于设置保护模式,在置位时开启。而 A20(Address 20) 是另一个控制位,用于让 x86 芯片接受高于 20 位的地址,而不是进行地址环绕。二者都是 x86 系列芯片为了兼容性而设计,但却相互独立,打开一者并不意味着打开另一者。
打开 A20 仅仅意味着 CPU 可以进行 32 位寻址,且最大寻址空间是 4GB。打开 PE 是进入保护模式,从而可能进行安全的系统编程,此时物理地址和线性地址一 一对应。A20 会控制 CPU 的第 21 位~第 32 位地址线,A20 未打开的时候,第 21 根及以上地址线被强制置为为 0,所以相当于 CPU “回滚”到内存地址起始处寻址。这是为了完全兼容以前在「只有 20 位寻址空间的 CPU 」上写的程序所设计的。
| 寻址情况 | 不打开 A20(上电默认状态) | 打开 A20 |
|---|---|---|
| 实模式 | cs:ip 最大寻址为 (0xFFFFF:0xFFFFF)%0x100000=0xFFEF |
可以寻址到 1MB 以上的高地址内存区 |
| 保护模式 | 只能访问奇数 1M 段,即 0-1M,2M-3M,4-5M 等 | 可以访问的内存是连续的 |
打开 A20 是打开 PE 的必要条件;而打开 A20 不一定非得打开 PE。显然,A20 和 PE 必须分别打开,否则保护模式将无法正常工作。
8. 在 setup 程序里曾经设置过 GDT,为什么在 head 程序中又将其废弃,重新设置了一个?为什么设置两次,而不是一次搞好?
第一次设置 GDT 所在的位置是在 setup.s 中,然而将来 setup 所在的内存位置会被缓冲区覆盖,如果不改变位置,GDT 的内容将被缓冲区覆盖掉,从而影响系统的运行。这样一来,将来整个内存中唯一安全的地方就是现在 head.s 所在的位置了。
那么有没有可能在执行 setup 程序时直接把 GDT 的内容复制到 head.s 所在的位置呢?答案是否定的。如果先复制 GDT 的内容、后移动 system 模块,GDT 会被后者覆盖;如果先移动 system 模块,后复制 GDT 的内容,它又会把 head.s 对应的程序覆盖,而这时 head 还没有执行。所以,无论如何,都要重新建立 GDT。
system模块是指内核在内存中的映像。
9. 用户进程自己设计一套 LDT 表,并与 GDT 挂接,是否可行,为什么?
不可行。
首先,用户进程不可以设置 GDT、LDT,因为 Linux-0.11 将 GDT、LDT 这两个数据结构设置在内核数据区,是 0 特权级的,只有 0 特权级的代码才能修改设置 GDT、LDT。因此,用户进程不能直接修改已存在的 GDT、LDT。
而且,用户也不可以在自己的数据段按照自己的意愿重新做一套 GDT、LDT。如果仅仅是形式上做一套和GDT、LDT一样的数据结构是可以的,但是真正起作用的 GDT、LDT 是 CPU 硬件认定的,这两个数据结构的首地址必须挂载在 CPU 的 %GDTR、%LDTR 寄存器上,运行时 CPU 只认 %GDTR 和 %LDTR 指向的数据结构,其他数据结构就算起名字叫 GDT、LDT,CPU 也一概不认;另外,用户进程也不能将自己制作的 GDT、LDT 挂接到 GDRT、LDRT 上,因为对 %GDTR 和 %LDTR 的设置(lgdt等指令)只能在 0 特权级别下执行,3 特权级别下无法把这套结构挂接到 %GDTR 和 %LDTR 上。
10. setup.s 程序里的 cli 是为了什么?
cli 是关中断指令,意味着程序在接下来的执行过程中,系统不会对中断进行响应。原因很简单:在 setup 程序中,操作系统将要重新设置中断向量表和中断服务程序,在这个过程中是无法进行正常中断的。因此,操作系统先将中断关闭,直到中断重新设置完成后再打开中断,即运行 sti 指令。
在 setup 中,需要将位于 0x10000 的内核程序复制到 0x00000 处,BIOS 创建的原生中断向量表覆盖掉了。若此时产生中断,将产生不可预知的错误,所以要禁止中断。此外,此时也是由 16 位实模式向 32 位保护模式转变的时候,需要在保护模式下重新建立中断描述符表的交接工作,正是实模式的中断机制向保护模式的中断机制交接的时候。在保护模式的中断机制尚未完成时不允许响应中断,以免发生未知的错误。
11. 进程 0 的 task_struct 在哪?具体内容是什么?
进程 0 的 task_struct 位于内核数据区,因为在进程 0 未激活之前,使用的是 boot 阶段的 user_stack,因此存储在 user_stack 中。 具体内容:包含了进程 0 的进程状态、进程 0 的 LDT、进程 0 的 TSS 等等。其中 LDT 设置了代码段和堆栈段的基址和限长(640KB),而 TSS 则保存了各种寄存器的值,包括各个段选择符。
代码如下:
1 | // 代码路径:include/linux/sched.h |
12. 内核的线性地址空间是如何分页的?画出从 0x000000 开始的7个页(包括页目录表、页表所在页)的挂接关系图。页目录表的前四个页目录项、第一个页表的前7个页表项指向什么位置?给出代码证据。
如何分页:head.s 在 setup_paging 开始创建分页机制。将页目录表和4个页表放到物理内存的起始位置,从内存起始位置开始的5个页空间内容全部清零(每页4KB),然后设置页目录表的前4项,使之分别指向4个页表。然后开始从高地址向低地址方向填写4个页表,依次指向内存从高地址向低地址方向的各个页面。即将第4个页表的最后一项指向寻址范围的最后一个页面。即从 0xfff000 开始的 4KB 大小的内存空间。将第4个页表的倒数第二个页表项指向倒数第二个页面,即 0xfff000-0x1000000 开始的4KB字节的内存空间,依此类推。
挂接关系图:
![内核的页目录表和页表[2]](/2022/12/31/Linux-0-11-%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E4%B8%8E%E6%80%9D%E8%80%83%E9%A2%98/paging.jpeg)
代码证据:
注意,页目录表需指向所有页表;页表须要指向所有页;页目录表、页表自己也是页。
1 | // 代码路径:boot/head.s |
13. 在 head 程序执行结束的时候,在 IDT 的前面有 184 个字节的 head 程序的剩余代码,剩余了什么?为什么要剩余?
在 IDT 前面有 184 个字节的剩余代码,剩余内容在 0x054b8~0x05400处,包含了 after_page_tables、ignore_int 中断服务程序和 setup_paging 设置分页的代码。其中 after_page_tables 往栈中压入了些参数,ignore_int 用做初始化中断时的中断处理函数,setup_paging则用于初始化分页。
剩余的原因:after_page_tables 中压入了一些参数,为内核进入 main() 函数跳转做准备,为了谨慎起见,设计者在栈中压入了 L6,以使得系统可能出错时,返回 L6 处执行。这部分代码可能返回,因此要放在页表后面。
ignore_int为中断处理函数,因此如果中断开启后,可能使用了未设置的中断向量,那么将默认跳转到ignore_int 处执行。因此不能被覆盖。
setup_paging 部分用于设置页表,在分页完成前不能被覆盖,因此放在页表的后面。
14. 为什么不用 call,而是用 ret “调用” main 函数?画出调用路线图,给出代码证据。
call 指令会将 %eip 的值自动压栈,保护返回现场,然后执行被调函数的程序,等到执行被调函数的 ret 指令时,自动出栈给 %eip 并还原现场,继续执行原来 call 后的下一条指令。然而对操作系统的 main() 来说,如果由 call 调用 main() 函数,那么函数最后返回给谁呢?在由 head 程序向 main 函数跳转时,是不需要 main 函数返回的;从逻辑上来说,main 作为任何 C 程序的主入口,也不应该返回到其它位置的——它本身就是最“基本”的函数。因此代码中没有使用 call 调用 main,而是手动压栈(模仿了 call 的全部动作),并“返回”至 main 函数。
具体来说,操作系统先通过手动压栈调用 setup_paging 函数,压栈的 %eip 值不是调用 setup_paging 函数的下一行指令的地址,而是 main() 的入口地址。当 setup_paging 函数执行到 ret 时,从栈中将 main() 的入口地址 _main 自动出栈给 %eip,%eip 指向 main 函数的入口地址,便实现了用返回指令调用 main 函数。这样以来,就通过 ret ——而不是 call 指令——将逻辑控制流转交给了 main 函数,在方法论上确保了 main 在整个操作系统中的核心地位。
![仿call示意图[2]](/2022/12/31/Linux-0-11-%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E4%B8%8E%E6%80%9D%E8%80%83%E9%A2%98/pseudo_call.jpeg)
代码参考:
1 | # 代码路径:boot/head.s |
15. Linux 是用 C 语言写的,为什么没有从 main 开始,而是先运行3 个汇编程序,道理何在?
通常用 C 语言编写的程序都是用户应用程序,这类程序的执行必须在操作系统上执行,也就是说要由操作系统为应用程序创建进程,并把应用程序的可执行代码从硬盘加载到内存。
然而,对于操作系统而言,在 BIOS 之后就要开始运行。但 CPU 启动时默认为16位的实模式(BIOS加载完之后仍然在实模式),开机时的 16 位实模式与 main 函数执行需要的 32 位保护模式之间有很大的差距。此时内存中没有操作系统程序,只有 BIOS 程序。操作系统需要借助 BIOS 分别加载 bootsect 、setup 及 system 模块,然后利用这 3 个程序来完成内存规划、建立 IDT 和 GDT、设置分页机制等等。其中 bootsect 负责加载,setup 与 head 则负责获取硬件参数,准备 IDT、GDT,开启 A20, PE, PG, 废弃旧的 16 位中断响应机制,建立新的 32 为 IDT,设置分页机制等,实现从开机时的 16 位实模式到 main 函数执行需要的 32 位保护模式之间的转换。当计算机处在 32 位的保护模式状态下时,调用 main 的条件才算准备完毕。
由此可见,在真正能调用一个 C 程序之前,还有大量的更为基本的准备工作要做,而这些准备工作往往需要更为底层的汇编语言来完成。因此,启动时需要先调用少量汇编程序,做好体系结构层级的基本准备之后再转入 C 语言编写的程序。
16. 用文字和图说明一个中断描述符表是如何初始化的,可以举例说明(比如:set_trap_gate(0,÷_error)),并给出代码证据。
对中断描述符表的初始化,就是将中断、异常处理的服务程序与 IDT 进行挂接,逐步重建中断服务体系。
以 set_trap_gate(0,÷_error) 为例,函数的原型为:
1 | // 代码路径:include/asm/system.h |
这是一个宏函数,展开到一般的门设置函数 _set_gate。其中,n 是 0,最终会指向 &idt[0],也就是 IDT 第一项中断描述符的地址;type 是 15(32位门,陷进门),dpl(描述符特权级)是 0;addr 是中断服务程序 divide_error(void) 的入口地址。
![参数对应示意图[2]](/2022/12/31/Linux-0-11-%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E4%B8%8E%E6%80%9D%E8%80%83%E9%A2%98/trap_init_param.jpeg)
最终真正进行 IDT 设置的代码是一段内嵌汇编代码,见下:
1 | // 代码路径:include/asm/system.h |
刚开始中断服务程序地址 ÷_error 存储在 %edx 中,段选择子 0008 存储在 %eax 的高字,将 %edx 低字赋给 %eax 的低字组成中断描述符表的低 32 位,0x8000+ (dpl<<13) + (type<<8) 即二进制1000111100000000是对 p 位、type 位、dpl 位的设置,然后赋给 %edx 的低位组成中断描述符表的高32位,最后将 %edx、%eax 分别写入中断描述符表的高32位和低32位。
17. 分析初始化IDT、GDT、LDT的代码。
IDT:
初始化各种异常处理服务程序的中断描述符,例如除零错误(
divide_error)、保护错误(general_protection)、页故障(page_fault)等等。将剩余的中断处理程序都都初始化为默认项,即将
int 0x11~0x2F的中断服务程序的指针设置为reserved。设置协处理器 x387 的 IDT 项。
允许主8259A中断控制器的 IRQ2、IRQ13 的中断请求。
设置并口(可连接接打印机)的 IDT 项。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29// 代码路径:kernel/traps.c
void trap_init(void)
{
int i;
set_trap_gate(0,÷_error); // 设置各类处理器异常的处理程序
set_trap_gate(1,&debug);
set_trap_gate(2,&nmi);
set_system_gate(3,&int3); /* int3-5 can be called from all */
set_system_gate(4,&overflow);
set_system_gate(5,&bounds);
set_trap_gate(6,&invalid_op);
set_trap_gate(7,&device_not_available);
set_trap_gate(8,&double_fault);
set_trap_gate(9,&coprocessor_segment_overrun);
set_trap_gate(10,&invalid_TSS);
set_trap_gate(11,&segment_not_present);
set_trap_gate(12,&stack_segment);
set_trap_gate(13,&general_protection);
set_trap_gate(14,&page_fault);
set_trap_gate(15,&reserved);
set_trap_gate(16,&coprocessor_error); // 协处理器中断
for (i=17;i<48;i++)
set_trap_gate(i,&reserved);
set_trap_gate(45,&irq13);
outb_p(inb_p(0x21)&0xfb,0x21); // 允许主8259A芯片的IRQ2中断请求
outb(inb_p(0xA1)&0xdf,0xA1); // 允许从8259A芯片的IRQ13中断请求
set_trap_gate(39,¶llel_interrupt); // 并口的中断项
}
GDT:
在系统启动的过程中,GDT 被初始化了不止一次。GDT 最后一次在 head.s 中被设置,随后便在系统运行中被一直沿用。
在 head.s 中,采用 lgdt 指令加载预设好的 GDT 表内容。在这里,内核只设置了 GDT 中内核数据段和内核代码段的段描述符,而各个任务的 LDT 和 TSS 段在以后设置。
代码如下:
1 | # 代码路径:boot/head.s |
最后,在 sched_init 中设置进程 0 的 LDT 段和 TSS 段。注意,进程 0 的 LDT 和 TSS 段的内容是在 sched.h 中预设的固定值。
1 | // 代码路径:kernel/sched.c |
LDT:
对进程 0 来说,LDT 的值是预设的(见下),在 sched_init 中被挂接到 GDT 上(见上)。
1 | // 代码路径:include/linux/sched.h |
对随后的进程来说,进程的 LDT 是在 fork 的过程中建立的。具体来说,在 copy_process 中内核为每一个新进程建立一套新的 LDT 和 TSS,内容与原进程一样:
1 | // 代码路径:kernel/fork.c |
随后如果有新的进程加载新的可执行程序(例如,开始执行 bash),那么 do_execve 会在加载新程序的同时写入新的 LDT 的内容。
18. CPL、RPL、DPL分别是什么意思?记录在什么位置?
CPL(Current Privilege Level) 指明当前执行程序/例程的特权级,是当前正在执行的代码所在的段的特权级。术语「当前特权级」就是指这个域的值。存在于 %cs 寄存器的低两位(%cs 段寄存器的第 0 和第 1 位)。
RPL(Request Privilege Level) 确定段选择子的请求特权级,是进程对段访问时的请求权限。RPL 是对于段选择子而言的,每个段选择子有自己的 RPL,它说明的是进程对段访问的请求权限,有点像函数参数。而且RPL对每个段来说不是固定的,两次访问同一段时的RPL可以不同。RPL可能会削弱CPL的作用,例如当前CPL=0的进程要访问一个数据段,它把段选择符中的RPL设为3,这样虽然它对该段仍然只有特权为3的访问权限。存在于段选择子的第 0 和第 1 位
DPL(Descriptor Privilege Level) 确定描述符的特权级,规定访问该描述符需要的权限级别。对段描述符,是访问这个段需要的特权级;对陷阱们和中断门,就是访问这些门、触发中断需要的特权级。当进程访问一个描述符时,需要进程特权级检查,一般要求 DPL >= max{CPL, RPL}。DPL 存在于段描述符的第二个双字的第 13 和第 14 位。
![Intel x86 架构中的段描述符格式,DPL 在第二个双字中的第 13 和 14 位[4]](/2022/12/31/Linux-0-11-%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E4%B8%8E%E6%80%9D%E8%80%83%E9%A2%98/seg_descr.jpg)
每个描述符的 DPL 固定,而请求时的 RPL 是可变的。只有当 RPL 比 DPL 相同或更高(数值上小于等于)时才能正常访问对应的段。
CPL, RPL, DPL 都是特权级。特权级数值越小,对应的特权越大;反之,数值越大,对应的特权越小。x86 体系结构中共设计了 4 级特权级,其中 0 特权级级别最高,意味着对芯片有着完全的掌控,一般由操作系统使用;3 特权级特权最低,只能执行简单的计算而无权染指系统指令,一般被赋予给应用程序使用。在 Linux-0.11 中,只使用了 0 特权级(作为内核特权级)和 3 特权级(供应用程序使用)。
19. 在IA-32中,有大约20多个指令只能在 0 特权级下使用,其他的指令,比如 cli,并没有这个约定。奇怪的是,在 Linux-0.11 中,3 特权级的进程代码并不能使用 cli 指令,这是为什么?请解释并给出代码证据。
根据 Intel IA-32 Manual,cli 和 sti 指令与 CPL 和 %eflags[IOPL](Input/Outpu Previledge Level, 进行IO操作需要的特权级)有关。通过 IOPL 来加以保护 in, ins, out, outs, cli, sti等 I/O 敏感指令,只有 CPL(当前特权级)<=IOPL 才能执行,低特权级访问这些指令将会产生一个一般性保护异常。IOPL 位于 %eflags 的12-13位,仅可通过 iret 和 lmsw 来改变。
操作系统上运行的第一个进程是进程 0,进程 0 的 IOPL 在 TSS 中初始化。INIT_TASK 中指定 %eflags[IOPL] 为0:
1 | // 代码路径:include/linux/sched.h |
从此之后,所有进程都直接或间接地由内核进程 fork 而来,IOPL 的值仍然为 0 没有改变,也不会改变。所以用户进程无法调用 cli 指令。因此,通过设置 IOPL,3 特权级的进程代码不能使用 cli 等I/O敏感指令。
1 | //代码路径:kernel\\fork.c |
20. 进程 0 的 task_struct 在哪?具体内容是什么?给出代码证据。
这一数据结构在代码上定义于 include/linux/sched.h,而运行时位于内核数据段。具体内容包括状态、信号、pid、alarm、ldt、tss 等管理该进程所需的数据。具体代码见问题 19。
21. 在 sched_init(void) 函数中有这样的代码,对 task 数组进行了初始化:
1 | // 代码路径:kernel/sched.c |
代码并未涉及 task[0],但从后续代码能感觉到进程 0 的任务结构已被设置,请给出代码证据。
上面的代码将 task[64] 除进程 0 占用的 0 项外的其余 63 项清空,等待随后被设置。其余进程的 task 数据结果都是在 fork 时被拷贝产生的,唯独进程 0 是个例外,它的 task 数据结构是在启动时手动设置的:
1 | // 代码路径:kernel/sched.c |
其中 init_task 是手动设置的进程 0 task 数据结构的值,见 include/linux/sched.h。
22. 在 system.h 里读懂代码。这里中断门、陷阱门、系统调用都是通过 _set_gate 设置的,用的是同一个嵌入汇编代码,比较明显的差别是 dpl 一个是3,另外两个是0,这是为什么?说明理由。
1 |
|
set_trap_gate 和 set_intr_gate 参数中的 dpl 是 3,set_system_gate的 dpl 是 0。dpl 为 0 表示只能在内核态下允许,dpl 为 3 表示系统调用可以由 3 特权级调用。 当用户程序产生系统调用软中断后, 系统都通过 system_call 总入口找到具体的系统调用函数。 set_system_gate 设置系统调用,须将 DPL 设置为 3,允许在用户特权级(=3)的进程调用,否则会引发保护异常。set_trap_gate 及 set_intr_gate 设置陷阱和中断为内核使用,需禁止用户进程调用,所以 DPL 为 0。
23. 在 Linux 操作系统中大量使用了中断、异常类的处理,究竟有什么好处?
在未引入中断、异常处理理念以前,CPU 采用轮询 (polling) 的方法处理外部信号:CPU 每隔一段时间就要对全部硬件进行轮询,以检测它的工做是否完成,若是没有完成就继续轮询。这样消耗了CPU处理用户程序的时间,下降了系统的综合效率。CPU以“主动轮询”的方式来处理信号是很不划算的。
自 IBM 兼容机以后,系统以“被动模式”代替“主动轮询”来处理终端问题。进程在主机中运算需用到 CPU,其中可能进行“异常处理”,此时需要具体的服务程序来执行。这种中断服务体系的建立是为了被动响应中断信号。因此,CPU 就可以更高效的处理用户程序服务,不用考虑随机可能产生的中断信号,从而提高了操作系统的综合效率。
24. 进程 0 fork 进程 1 之前,为什么先调用 move_to_user_mode()?用的是什么方法?解释其中的道理。
Linux 规定,除了进程 0 外,所有进程都要由一个已有的进程在 3 特权级下创建,进程 0 此时处于 0 特权级。按照规定,在创建进程 1 之前要将进程 0 转变为 3 特权级。方法是调用 move_to_user_mode() 函数,模仿中断返回动作,实现进程 0 的特权级从内核态转化为用户态。又因为在 Linux-0.11 中,转换特权级时采用中断和中断返回的方式,调用系统中断实现从 3 到 0 的特权级转换,中断返回时转换为 3 特权级。因此,进程 0 从 0 特权级到 3 特权级转换时采用的是模仿中断返回。设计者首先手工写压栈代码模拟 int(中断)压栈,当执行 iret 指令时,CPU 自动将这 5 个寄存器的值 (%ss, %esp, %eflags, %cs, %eip) 按序恢复给 CPU,CPU 就会翻转到 3 特权级去执行代码。
25. 为什么 static inline _syscall0(type,name) 中需要加上关键字 inline?
这一问题的答案藏在写时复制 (CoW, Copy on Write) 机制中。
fork 函数会复制进程的页表,并将父进程和子进程的页表项都标记为只读,从而便于随后实现写时复制功能。具体来说,进程试图读取只读页的时候会产生保护异常,操作系统便在处理异常时拷贝一份新的物理页供进程修改。但 CoW 机制有一个例外:当页在内核空间(1M以下的地址)时,不会进行写时复制,而是允许内核之间共享内存叶。导致这一行为的代码见 copy_page_tables(...) 函数:
1 | // 代码路径 mm/memory.c/copy_page_tables(...) |
进程 0 创建进程 1 后,二者共享物理页;然而由于栈和数据段位于内核区,如果进程 0 修改栈和数据段,不会触发写时复制,而是会在原有物理页上直接修改,这将破坏进程 1 的内存空间。为此,Linus 给出了解决方案:让进程 0 在 fork() 之后不修改任何数据和栈。
_syscall0(int, fork) 展开之后是一个真正的 C 函数声明。如果进程 0 直接调用这样的函数,那么势必会使用栈,从而破坏进程 1 的栈。为此,Linus Torvalds 在声明中加入了 inline 关键字,让编译器在 main 中原地展开函数声明。这样一来,运行时中就不会进行函数调用,也不会改变栈的内容,从而避免了破坏进程 1 的栈。
“函数调用”意味着什么呢?在汇编层次上,函数调用意味着 call 和 ret 指令。普通函数调用时需要使用 call 将 %eip 入栈(并跳转),返回时需要使用 ret 将 %eip 出栈,这都会修改栈的内容。inline 意味着内联函数,它将标明为 inline 的函数代码放在符号表中;此处的 fork 函数加上 inline 后先进行词法分析、语法分析后在编译时就地展开函数,不需要普通函数的 call\ret 指令,也不需要保持栈的 %eip。
若不加上 inline,(进程 0 中)第一次返回 fork 结束时会将 %eip 出栈,在 pause 时又将新的返回地址压入栈中。经过 pause 之后进程 1 才被调度执行,而此时的栈段已经被进程 0 修改过了,(进程 1 中)第二次 fork() 返回时 %eip 的出栈值将是一个错误值。
26. 缺页中断是如何产生的,页写保护中断是如何产生的,操作系统是如何处理的?
在 Intel x86 体系结果中,严格来说没有“缺页中断”,只有“页故障”(#PF, page fault),和页故障导致的软中断。缺页故障和页写保护故障分别是页故障的两种不同情况,由故障产生时的 error code 区分。
Linux-0.11 中,#PF 由 page.s 中的 _page_fault 进行初步处理,根据不同 error code 分别转交给 do_no_page (缺页故障)和 do_wp_page (页写保护故障)作进一步处理。
① 缺页故障
每一个页目录项或页表项的低 3 位,U/S, R/W, P,记录着所管理的页面的属性。如果页目录项或页表项指向的页存在于物理内存中,则 P 标志就设置为 1,反之则为 0。进程执行时,线性地址由 MMU 负责解析,如果解析发现某个表项的 P 位为 0,则说明没有对应页面,便会产生缺页中断。操作系统会调用 do_no_page 处理缺页故障:为进程申请空闲物理页,将程序加载到新分配的物理页中,并更新对应的页目录项和页表项。
② 页写保护故障
若某个进程试图访问一个只读页面(R/W 为 0),便会产生一个页写保护故障。这种情况往往是由于采用了 CoW(写时复制,Copy on Write)策略、两个(或多个)进程共享一个页面导致的。在 copy_page_tables 函数中,操作系统会将被两个进程共享的页面标记为只读。任何一个进程试图修改只读页时,便会触发页写保护故障,这便是两个(或多个)进程共享一个页面的具体原理。检测到页写保护故障后,操作系统会调用 do_wp_page 实现写时复制策略:为当前进程申请空闲物理页,将将原页面的数据复制到新页面中,然后将该进程的页表项指向新申请的页面,同时将原页面的引用计数减 1。当前进程得到自己的页面,就可以执行写操作。
Part II 多任务与进程调度
27. copy_process 函数的参数最后五项是:long eip,long cs, long eflags, long esp, long ss。查看栈结构确实有这五个参数,奇怪的是其他参数的压栈代码都能找得到,确找不到这五个参数的压栈代码,反汇编代码中也查不到,请解释原因。
copy_process 执行是因为进程调用了 fork 函数创建进程,会执行 int 0x80 产生一个软中断。参考 Intel IA-32 手册可知,中断使 CPU 硬件自动将 %ss, %esp, %eflags, %cs, %eip 这5个寄存器的值按顺序压入进程0的内核栈。又因为函数传递参数是使用栈的,所以刚好可以作为 copy_process的 最后五个参数。
28. 根据代码详细说明 copy_process 函数的所有参数是如何形成的?
copy_process 函数原型为:
1 | int copy_process(int nr,long ebp,long edi,long esi,long gs,long none, |
与一般的函数不同,copy_process 的参数不是由 C 语言中的传参机制传递的,而是由汇编代码“做”出来的。函数参数的本质是调用子程序时的栈上数据,而 copy_process 函数的所有参数正是通过汇编代码压栈形成的。
参数有很多,我们将其分为几组,分组进行讨论。
① long eip, long cs, long eflags, long esp, long ss 这五个参数是中断使 CPU 自动压栈的。参考 x86 手册 (Intel IA-32 Manual) 可知,在中断时芯片会自动将当前的 %eip, %cs, %eflags 压入栈中,便于从中断处理程序返回到原来执行处。如果中断时切换了特权级,还会将 %esp 和%ss 压入栈中,并切换栈。
系统调用是从 3 特权级的用户态向 0 特权级的内核态的切换,因此会触发后一种压栈,形成了 copy_process 的后五个参数。
![IA-32 CPU在中断时的自动压栈[4]](/2022/12/31/Linux-0-11-%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E4%B8%8E%E6%80%9D%E8%80%83%E9%A2%98/stack_change_on_int.png)
② long ebx, long ecx, long edx, long fs, long es, long ds 是在汇编代码中压进栈的参数。
③ long none 是一个无用参数,起占位符作用。 为 _system_call 调用 _sys_fork 时压进栈的 %eip 值。
④ int nr 是 _system_fork 压入栈的值,也是 find_empty_process 函数的返回值。这个值是 task 数组中下一个空槽位的索引。
⑤ long ebp, long edi, long esi, long gs 是 _system_fork 压入栈的参数。
不难发现,除了 int nr 和 int none 之外,其余的参数都对应了用户态程序调用 fork 之前的寄存器值。这些寄存器值被传递给 copy_process,是为了被拷贝到新进程。
1 | // 代码路径:kernel/system_call.s |
29. 进程 0 创建进程 1 时调用 copy_process 函数,在其中直接、间接调用了两次 get_free_page 函数,在物理内存中获得了两个页,分别用作什么?是怎么设置的?给出代码证据。
第一次调用 get_free_page 函数申请的空闲页面用于进程 1 的 task_struct 及内核栈。首先将申请到的页面清0,然后复制进程 0 的 task_struct,再针对进程 1 作微调。其中 esp0 的设置,意味着设置该页末尾为进程 1 的内核栈的起始地址。
1 | // 代码路径:kernel/fork.c |
第二次调用 get_free_page 函数申请的空闲页面用作进程 1 的页表。在创建进程1执行 copy_process 中,执行 copy_mem(nr,p) 时,内核为进程 1 拷贝了进程 0 的页表(对进程 0 ->进程 1而言只拷贝 160 页表项,否则会拷贝 256 项),同时将页表项的属性修改为只读。
1 | // 代码路径:mm/memory.c |
30. 分析 get_free_page() 函数的代码,叙述在主内存中获取一个空闲页的技术路线。
- 通过逆向扫描页表位图
mem_map,找到内存中(从高地址开始)第一个空闲(字节为0)页面,将其在mem_map中对应的位置置为1。 %ecx左移12位加LOW_MEM获得该页的物理地址,并将页面清零。- 最后返回空闲页面物理内存的起始地址。
值得注意的是,代码中利用了x86架构提供的字符串批处理指令 (scasb, stosl),以简化代码、加快速度。
代码如下:
1 | // 代码路径:mm/memory.c |
31. 为什么 get_free_page() 将新分配的页面清 0?
因为无法预知该内存页的用途,如果用作页表,不清零就有垃圾值,就是隐患。
Linux 在回收页面时并不会将页面清 0,只是将 mem_map 中与该页对应的引用计数置 0。在使用 get_free_page 申请内存页时,便是遍历 mem_map 寻找引用计数为 0 的页,但是该页可能存在垃圾数据,如果不清 0 的话,若将该页用做页表,则可能导致错误的映射,引发错误,所以要将新分配的页面清0。
32. copy_mem() 和 copy_page_tables() 在第一次调用时是如何运行的?
copy_mem() 在进程 0 创建进程 1 时被第一次调用,它的作用是拷贝进程的内存管理框架,设置进程 1 的段描述符。它先提取当前进程(进程0)的代码段、数据段的段限长,并将当前进程(进程0)的段限长赋值给子进程(进程1)的段限长。然后提取当前进程(进程0)的代码段、数据段的段基址,检查当前进程(进程0)的段基址、段限长是否有问题。接着设置子进程(进程1)的 LDT 段描述符中代码段和数据段的基地址为 nr(=1)*64MB。最后调用 copy_page_tables() 函数,进行具体的页表拷贝。
copy_page_tables() 的作用是拷贝进程的页目录项和全部页目录表,但不拷贝物理页。该函数的参数是源地址、目的地址和大小,首先检测源地址和目的地址是否都是 4MB 的整数倍,如不是则报错,不符合分页要求。然后取源地址和目的地址所对应的页目录项地址,检测如目的地址所对应的页目录表项已被使用则报错,其中源地址不一定是连续使用的,所以有不存在的跳过。接着,取源地址对应的页表地址,并为目的地址申请一个新页作为子进程的页表。然后,判断源地址是否为 0,即父进程是否为进程 0 ,如果是,则复制160个页表(~640KB),否则复制1024个页表(~4MB)。最后将源页表项复制给目的页表。按理说源页表项和目的页表项都应将对应的页标记为“只读”、方便后续进行写时复制操作,但由于是第一次调用,所以父进程是0,都在1M内,所以不参与写时复制,也不维护引用计数 mem_map。1M内的内核区不参与用户分页管理。对 copy_page_tables 函数的具体分析见问题 33。
33. 分析 copy_page_tables() 函数的代码,叙述父进程如何为子进程复制页表。
进入 copy_page_tables 函数后,先为新的页表申请一个空闲页面,并把进程 0 中第一个页表里的前 160 个页表项复制到这个页面中(1个页表项控制一个页面 4KB 内存空间,160个页表项能够控制 640KB 内存空间)。进程0和进程1的页表暂时度指向了相同的页面,意味着进程1也能够操做进程0的页面。以后对进程1的页目录表进行设置。最后,用重置 %cr3 的方法刷新页面变换高速缓存 (TLB)。进程 1 的页表和页目录表设置完毕。进程 1 此时是一个空架子,尚未对应的程序,它的页表又是从进程 0 的页表复制过来的,它们管理的页面彻底一致,也就是它暂时和进程 0 共享一套页面管理结构。
1 | // 代码路径:kernel/fork.c |
34. 进程 0 创建进程 1 时,为进程 1 建立了 task_struct 及内核栈,第一个页表,分别位于 16MB 物理内存的末尾倒数第一页、第二页。请问,这两个页究竟占用的是谁的线性地址空间,内核、进程 0、进程 1、还是没有占用任何线性地址空间?说明理由(可以图示)并给出代码证据。
均占用内核的线性地址空间。
需要分页内存时,内核通过调用 get_free_page() 获得空页。而正如前面(问题19)分析,get_free_page()通过逆向扫描页表位图,找到第一个空页后返回,因此得到的内存页位于 16M 内存末端。 代码如下:
1 | // 代码路径:mm/memory.c |
进程 0 和进程 1 的 LDT 的限长属性将进程 0 和进程 1 的地址空间限定 0~640KB, 所以进程 0、 进程 1 均无法访问到这两个页面, 故两页面占用内核的线性地址空间。进程 0 的局部描述符如下:
1 | // 代码路径:boot/head.s |
上面的代码,指明了内核的线性地址空间为 0x000000~0xffffff(即前16M),且在内核的视角中,线性地址与物理地址一一对应。为进程1分配的这两个页,在16MB的顶端倒数第一页、第二页,因此占用内核的线性地址空间。 进程 0 的线性地址空间是内存前 640KB,因为进程 0 的 LDT 中的 limit 属性限制了进程 0 能够访问的地址空间。进程 1 拷贝了进程 0 的页表(160项),而这160个页表项即为内核第一个页表的前160项,指向的是物理内存前 640KB,因此无法访问到 16MB 的顶端倒数的两个页。 进程 0 创建进程 1 的时候,先后通过get_free_page函数从物理地址中取出了两个页,但是并没有将这两个页的物理地址填入任何新的页表项中。此时,只有内核的页表中包含了与这段物理地址对应的项,也就是说此时只有内核可以访问到这两个页,所以这两个页占用了内核线性空间。
这里的进程 0 是指处在用户态的进程 0。而内核则是运行在所有进程中运行在 0 特权级的那部分。
35. 内核和普通用户进程并不在一个线性地址空间内,为什么仍然能够访问普通用户进程的页面?
内核的线性地址空间和用户进程不一样,内核是不能通过跨越线性地址访问进程的。但由于早就占有了所有的页面,而且特权级是 0,所以内核执行时,可以对所有的内容进行改动,“等价于”可以操作所有进程所在的页面。
内核在启动时便在所有内存上(16M)建立了恒等映射的页表,因此内核通过这套页表可以访问所有内存页面。而对于随后建立的用户进程,每个进程有独立的 LDT,其中记录了进程拥有的线性地址段的起始和限长,每个用户进程对应了不同的页表。用户进程只能通过自己的 LDT 访问自己的页表、进而访问物理内存。在合适地地址设置之下,用户进程便无法访问其它进程的地址空间。
36. 假设:经过一段时间的运行,操作系统中已经有5个进程在运行,且内核分别为进程 4、进程 5 分别创建了第一个页表,这两个页表在谁的线性地址空间?用图表示这两个页表在线性地址空间和物理地址空间的映射关系。
这两个页面均占用内核的线性地址空间。既然是内核线性地址空间,则与物理地址空间为一一对应关系。根据每一个进程占用 16 个页目录表项,则进程 4 占用从第 65~80 项的页目录表项。同理,进程 5 占用第 81~96 项的页目录表项。因为目前只分配了一个页面(用作进程的第一个页表),则分别只须要使用第一个页目录表项便可。又因为物理页是从后向前分配的,因此进程 5 的第一个页表其实在进程 4 的前面。映射关系如图:
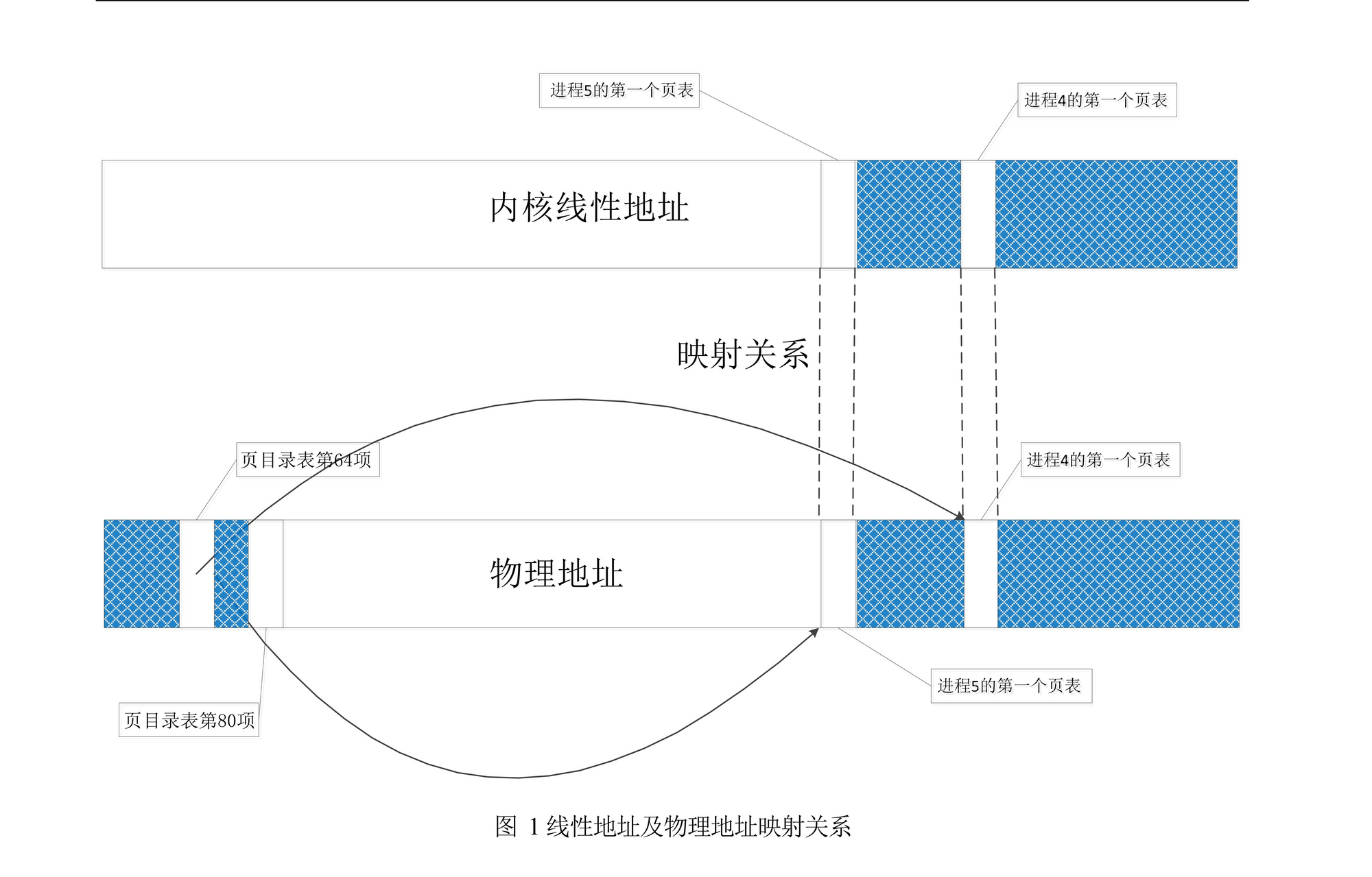
37. switch_to() 代码中的 ljmp %0\n\t 很奇怪,按理说 jmp 指令跳转到得位置应该是一条指令的地址,可是这行代码却跳到了 "m" (*&__tmp.a),这明明是一个数据的地址,更奇怪的,这行代码竟然能正确执行。请论述其中的道理。
1 | // 代码路径:include/linux/sched.h |
这个问题要由 Intel x86 体系结构来回答。80286及以后的x86系列处理器支持多任务,可以在硬件层面上完成任务切换。Intel x86 Manual 指出,可以通过1)跳转至任务门或者2)跳转至任务 TSS 对应的段选择子等方式来进行任务跳转。在这一过程中,由硬件负责保护现场、维护TSS、控制流跳转等工作。因此,ljmp %0\\n\\t实际上运用了 CPU 的多任务能力来完成任务切换,而不能简单地理解为跳转指令。
ljmp %0\\n\\t 未使用任务门,而是通过第二种方式(跳转至指向 TSS 的段选择子)进行任务切换。在这一条指令中:
- CPU 自动将当前各个寄存器值保存在进程 0 的 TSS 中,
- 将进程1的 TSS 中的各项数据(包括通用寄存器、LDT 中保存的的代码段、数据段描述符等)恢复给 CPU 的各个寄存器,
- 将控制流转移给进程 1(移交给进程 1 的
tss.eip)。如果深究系统初始化过程,可以发现切换后%eip指向的就是main中inline fork中的if(__res >= 0)语句。 - 并从0特权级的内核代码切换到3特权级。
38. 根据代码详细分析,进程 0 是如何根据调度第一次切换到进程1的?
进程 0 切换到进程 1,经历了两个过程:
- 进程 0 通过
fork函数创建进程 1,并使其处在就绪态。 - 进程 0 调用
pause函数。pause函数通过int 0x80中断跳转到sys_pause函数,将进程 0 自身设为可中断等待状态 (TASK_INTERRUPTIBLE),然后调用schedule函数进行进程调度。schedule函数遍历所有进程,比较进程的运行状态和剩余时间片,找出处于就绪态且剩余时间片最多(即counter最大)的进程。此时操作系统上只有进程 0 和进程 1,且进程 0 是挂起状态(可中断等待状态),只有进程 1 是就绪态,于是切换到进程 1 执行。 - 最终在
schedule函数中调用switch_to(1)(见问题 37 ——前一个问题]),通过 x86 芯片提供的任务切换接口切换到进程 1。
参考代码:
1 | // 代码路径:init/main.c |
39. 进程 0 进行简单初始化后,通过调用 fork() 创建进程 1。跟踪代码时我们发现,fork代码执行了两次,第一次,执行 fork 代码后,跳过 init() 直接执行了 for(;;) pause();,第二次执行 fork 代码后,执行了 init()。奇怪的是,我们在代码中并没有看到向转向 fork 的 goto 语句,也没有看到循环语句,是什么原因导致 fork 反复执行?请说明理由(可以图示),并给出代码证据。
在 Unix 标准中,fork() 是唯一一个调用一次、返回两次的函数。这是由其函数功能决定的:fork 创建了一个与父进程一模一样的新进程,因此在两个进程中势必都会返回一次。为了区分父子进程,fork 在父进程返回子进程的 pid,在子进程返回 0。通过调度后两个进程都会从 fork 处继续执行,随后便根据不同的返回值在 if 处走向了不同的分支。
然而作为一门操作系统课程,仅在用户角度分析 fork 是不够的。下面试从操作系统代码的角度做具体分析。
main.c 中的 fork 为特别处理的 inline 函数,其中调用了 int 0x80 产生系统中断,并最终跳转至内核中的copy_process函数。系统中断时,CPU 自动将 %ss, %esp, %eflags, %cs, %eip 压栈,其中 %eip 为 int 0x80 的下一指令的地址。在 copy_process 中,内核将进程 0 的 TSS 复制得到进程 1 的 TSS,并将进程 1 的 tss.eax 手动设为 0,而将进程 1 的pid(last_pid)返回给进程 0。在进程调度时 TSS 中的值被恢复至相应寄存器中,包括 %eip, %eax 等。所以中断返回后,进程 0 和进程 1 均会从 int 0x80 的下一句开始执行,即 fork 返回了两次。
由于 %eax 代表返回值,所以进程 0 和进程 1 会得到不同的返回值,在 fork 返回到进程0后,进程 0 判断返回值非 0,因此执行代码 for(;;) pause();
在 sys_pause 函数中,内核设置了进程0的状态为 TASK_INTERRUPTIBLE,并进行进程调度。由于只有进程1处于就绪态,因此调度执行进程 1 的指令。由于进程 1 在 TSS 中设置了 %eip 等寄存器的值,因此从 int 0x80 的下一条指令开始执行,且设定返回 %eax 的值作为 fork 的返回值(值为 0),因此进程1执行了 init() 所在的分支。
参考代码如下:
1 | // 代码路径:init/main.c |
40. 详细分析进程调度的全过程。考虑所有可能(signal、alarm除外)
Case I 有就绪进程,且时间片没有用完
正常情况下,schedule() 函数首先扫描任务数组。通过比较每个就绪任务(即处于 TASK_RUNNING 状态的进程)的剩余时间片数(即运行时间滴答计数 counter) 来确定哪个进程运行的时间最少。哪一个进程的值大,就表示运行时间还不长,于是选中该进程,调用 switch_to() 执行实际的进程切换操作
Case II 有就绪进程,但所有就绪进程的时间片都已用完(对应 schedule() 中 c==0 分支)
若此时所有就绪进程的时间片都已经用完,系统就会根据每个进程的优先权值 priority ,对所有进程(包括正在睡眠的进程)重新分配时间片。计算公式为:
对时间片已经用完的就绪进程,计算后会得到数值等于 priority 的时间片;对睡眠进程,剩余时间片会增加,剩余时间片数最终会收敛至 priority 的2倍。
然后 schdeule() 函数重新扫描任务数组中所有处于 TASK_RUNNING 状态的进程,重复上述过程,直到选择出一个进程为止,最后调用 switch_to() 执行实际的进程切换操作。
Case III 无就绪进程( 退出循环后next==0, c==-1 )
对操作系统来说这种情况看起来有些奇怪。但事实上是很有可能发生的。例如你运行了一个应用程序,但它正在控制台等待你的输入(例如正在运行 scanf 语句)而被挂起。
此时 schedule() 函数中的 c==-1,next==0,跳出循环后,执行 switch_to(0),即切换到进程 0 继续执行,即使此时进程 0 处于挂起状态。总之所有进程都不就绪时系统会执行进程 0 陷入空循环,而不是调用芯片的 nop指令。因此,进程 0 在有些操作系统上又被称为 「System Idle Process」。
参考代码:
1 | // 代码路径:kernel/sched.c |
41. 详细分析一个进程从创建、加载程序、执行、退出的全过程。
创建进程,调用fork函数。(详见
copy_process函数)a) 准备阶段,为进程在
task[64]找到空闲位置,即find_empty_process();b) 为进程管理结构找到储存空间:task_struct和内核栈。
c) 父进程为子进程复制
task_struct结构d) 为新进程复制页表及其其对应的页目录项(但不复制页表指向的内存页)
e) 为新进程设置新的段,并设置 LDT
f) 在新旧进程之间共享打开的文件
g) 将新进程的 TSS 和 LDT 挂载到全局描述符表 GDT 上
h) 将新进程设为就绪态
加载进程(对应
execve函数)a) 检查参数和外部环境变量和可执行文件
b) 释放进程的页表
c) 重新设置进程的程序代码段和数据段
d) 调整进程的
task_struct进程运行(运行新程序遭到缺页中断)
a) 进程的代码实际未被加载到内存中;试图执行代码时产生缺页中断并由操作系统响应
严格来说是经过编译后的机器码,不是代码
b) 为进程申请一个物理内存页
c) 将程序代码加载到新分配的页面中
d) 将物理内存地址与线性地址空间对应起来
e) 不断通过缺页中断加载进程的全部内容
f) 运行时如果进程内存不足继续产生缺页中断,往复执行这一过程
进程退出
a) 进程先处理退出事务
b) 释放进程所占页面
c) 解除进程与文件有关的内容并给父进程发信号
d) 进程退出后执行进程调度
42. 详细分析多个进程(无父子关系)共享一个可执行程序的完整过程。
为了便于分析,我们假设:
三个进程是通过
fork+execve的经典方式执行的三个进程执行间隔很短——例如,通过
bash脚本执行同一可执行文件的多个副本。程序执行的速度远大于外存读取的速度,且基本是顺序执行,不会在一小段代码中反复循环。
开机后该执行程序还没有执行过,在缓冲区中没有缓存。
㈠ execve 加载程序头部
假设有三个进程 A、B、C,进程 A 先执行,之后是 B 最后是 C,它们没有父子关系。A 进程启动时会调用 execve 函数打开新的可执行文件,然后调用 bread_page() 函数读取文件开头的内容。bread_page 函数会分配缓冲块,进行设备到缓冲块的数据读取。因为此时为设备读入,时间较长,所以会给该缓冲块加锁,调用 sleep_on 函数,A进程被挂起,调用 schedule(), B 进程开始执行。
B进程也首先执行 execve() 函数。B 进程调用 execve 函数,同样会调用 bread_page(),由于此时内核检测到 B 进程需要读的数据已经进入缓冲区中,则直接返回。但是由于此时设备读没有完成,缓冲块已被加锁,所以 B 将因为等待而被系统挂起,之后调用 schedule() 函数。
C 进程开始执行,但是同 B 一样,被系统挂起,调用 schedule() 函数,假设此时无其它进程,则系统进程 0 开始执行。
等到读操作完成,外设产生中断,中断服务程序开始工作。它给读取的文件缓冲区解锁并调用 wake_up() 函数,传递的参数是 &bh->b_wait,该函数首先将 C 唤醒,此后中断服务程序结束,开始进程调度。此时 C 就绪,C 程序开始执行,并将 B 进程设为就绪态。C 执行结束或者 C 的时间片削减为 0 (严格来说, C 中调用到 schedule() 也会导致进程切换——但我们先忽略这种情况) 时,切换到 B 进程执行。进程 B 也在 sleep_on() 函数中,调用 schedule 函数进程进程切换后,B 最先回到 sleep_on 函数,进程 B 开始执行,并将进程 A 设为就绪态。同理当 B 执行完或者时间片削减为 0 时,切换到进程 A 执行。此时 A 的内核栈中 sleep_on().tmp 对应 NULL,不会再唤醒进程了。
㈡ 缺页中断加载随后的程序片段
可执行程序的最开头部分由 do_execve 调用 bread_page 读入内存,但其它的部分则不会立马读入内存,而是被运行到时才读取。这种 lazy loading 机制(在源码注释中称为“demand-loading”)让程序只在真正运行到时才被加载进入内存,提高了操作系统创建进程的效率。此时,触发文件加载的不再是 execve,而是缺页中断。
严格来说内存页遇到问题产生的中断不是“缺页中断”,而是“页故障”(page fault),后者才是 Intel 体系结构中的名称。前面
假设进程 C 被唤醒之后一路高歌猛进,在进程切换前直接执行到了未被加载的页。此时处理器触发页故障软中断,调用页故障处理程序。页故障处理程序根据页故障的 error code 判断是缺页故障(见 mm/page.s),跳转到 do_no_page 函数执行。do_no_page 函数首先根据缺失页的线性地址计算出需要读取的设备块编号,然后调用 bread_page 读取至空闲的物理页,最后调用 put_page 将物理页映射到 C 的线性地址空间。
在 bread_page 的过程中又会进入 sleep_on,轮到进程 B 执行。很快,进程 B 也遇到了同样问题(缺页),同样来到 do_no_page 执行类似的逻辑。此时若 C 中请求的页已经读取完毕,do_no_page 会共享相同的页,直接返回继续执行。若此时 C 请求的页尚未读取完毕,则进程 B 的缺页中断处理程序仍会调用 bread_page ,请求相同的页,调用 sleep_on() 挂起运行。最后,进程 A 的情况与进程 B 是类似的。
由此可见,进程 A、B、C 会在“运行、缺页中断、运行、缺页中断……”的循环中轮流执行。
最后要强调的是,依次创建的 3 个用户进程,每个进程都有自己的 task 数组项。三个进程虽然共享程序数据,但栈和数据相互独立。操作系统使用不同的 TSS 和 LDT 实现对进程的保护,不同的进程无法相互访问对方的地址空间。
43. 打开保护模式和分页后,逻辑地址到物理地址是如何转换的?
打开保护模式后,x86 处理器开始按段寻址,先按段寄存器中的值选择一个段,然后将逻辑地址加上段基址形成线性地址。若不打开分页,此时的线性地址就是物理地址,处理器会直接根据线性地址到内存中寻址。
![逻辑地址与线性地址的转换关系[4]](/2022/12/31/Linux-0-11-%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E4%B8%8E%E6%80%9D%E8%80%83%E9%A2%98/seg_addressing.png)
打开分页后,线性地址需要进一步经过页表的转换才会变换为物理地址。分页机制在线性地址和物理地址之间增加一层新的 indirection,线性地址又成为了“虚拟地址”。
保护模式下,每个线性地址为 32 位,MMU 按照 10-10-12 的长度来识别线性地址的值。%cr3 中存储着页目录表的基址,线性地址的前 10 位指向页目录表中的页目录项,由此得到对应的页表地址。中间 10 位记录了页表中的页表项位置,由此得到页的位置,最后 12 位表示页内偏移。
![线性地址与物理地址的转换关系——开启分页后[2]](/2022/12/31/Linux-0-11-%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E4%B8%8E%E6%80%9D%E8%80%83%E9%A2%98/page_addressing.jpeg)
同时开启分段(即保护模式)和分页后,完整的地址转换如下图所示:
![完整的段页模式地址转换示意图[4]](/2022/12/31/Linux-0-11-%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E4%B8%8E%E6%80%9D%E8%80%83%E9%A2%98/seg_and_paging_addressing.png)
Part III 高速缓冲区
44. 为什么要设计缓冲区,有什么好处?
设计缓冲区的核心思想在于局部性原理:如果一段代码或数据在最近被使用过,那它在随后就很有可能被再次使用。
在计算机中,内存间的读取速度比外部存储设备(e.g. 硬盘)的读取速度快 2~3 个数量级。如果某个进程将硬盘数据读到缓冲区之后,其他进程刚好也需要读取这些数据,那么就可以直接从缓冲区中读取,大大加快读取速度。如果某个进程将新数据写到缓冲区之后,其他进程刚好也需要修改这些数据,那么就可以直接在缓冲区中修改,避免多次写入硬盘。直接从缓冲区读写的数据越多,计算机的整体性能就会越高。
此外,缓冲区页构成所有块设备数据的统一集散地,使操作系统的设计更方便,更灵活。
45. getblk 函数中,申请空闲缓冲块的标准就是 b_count 为 0,而申请到之后,为什么在 wait_on_buffer(bh) 后又执行if(bh->b_count) 来判断 b_count 是否为0 ?
1 | // 代码路径:fs\\buffer.c |
wait_on_buffer(bh) 内包含睡眠函数,在睡眠中可能已有其它进程执行过。睡眠唤醒后,之前找到的比较合适的空闲缓冲块可能在睡眠阶段又被其他任务所占用,因此必须重新判断是否被修改。若判断被占用则回到 repeat,重新获取资源。
字段 b_count 用于标记「每个缓冲块有多少个进程在共享」。只有当b_count==0 时,该缓冲块才能被再次分配。
举一个可能引发异常的例子:每个缓冲块有一个进程等待队列,假设此时 B、C 两进程在队列中,当该缓冲块被解锁时,进程C被唤醒(它开始使用缓冲区之前需先唤醒进程 B,使进程 B 从挂起进入就绪状态),将缓冲区加锁。一段时间后,进程C又被挂起,但此时缓冲区由进程 C 在使用。此时,若进程B被调度,
if (bh->b_count)会注意到该缓冲区任是加锁状态,从而进程 B 重新选择缓冲区。如果没有这一额外判断,将造成进程 B 操作一个被加锁的缓冲区,引发异常。
这一问题的本质在于竞争条件,是操作系统编程和并发编程中的一大难题。
46. b_dirt 已经被置为1的缓冲块,同步前能够被进程继续读、写吗?为什么?给出代码证据。
这样的缓冲块在同步前能够被继续读、写。 缓冲块是否能被进程读写,并不取决于 b_dirt,而取决于b_uptodate。只要 b_uptodate 为 1,缓冲块就能被进程读写。
这一设计背后的根源在于,我们并不在乎缓冲区是否与硬盘上的数据同步,而是希望缓冲区上的数据总是最新的,只有这样缓冲区才能成为硬盘数据的缓存。
具体来说,读操作不会改变缓冲块中数据的内容,写操作后,改变了缓冲区内容,需要将 b_dirt 置 1 ,为后面的写回做准备。而b_uptodate 设置为1后,内核便支持进程共享该缓冲块的数据了,读写均可。读操作不会改变缓冲块的内容,所以不影响数据;而执行写操作后,就改变了缓冲块的内容,就要将 b_dirt 标志设置为 1 。由于之前缓冲块已经和硬盘块更新了,所以后续同步过程中『缓冲块没有写入新数据的部分』和『原来硬盘对应的部分』相同,向硬盘同步时,所有的数据都是进程希望同步到硬盘数据块上的,不会把垃圾数据同步到硬盘上去。所以 b_uptodate 仍为 1 。所以, b_dirt 为 1 ,进程仍能对缓冲区进行读写。
代码证据:
1 | //代码路径:fs/block_dev.c |
47. 分析 panic() 函数的源代码,根据你学过的操作系统知识,完整、准确的判断 panic() 函数所起的作用。假如操作系统设计为支持内核进程(始终运行在0特权级的进程),你将如何改进 panic() 函数?
panic() 函数是当系统发现无法继续运行下去的故障时将调用它,会导致程序终止,然后由系统显示错误号。如果出现错误的函数不是进程0,那么就要进行数据同步,把缓冲区中的数据尽量同步到硬盘上。遵循了 Linux 尽量简明的原则。 改进 panic 函数:将死循环 for(;;); 改进为跳转到内核进程(始终运行在 0 特权级的进程),让内核继续执行。
1 | // 代码路径:kernel/panic.c |
48. wait_on_buffer函数中为什么不用 if(...) 而是用 while(...) ?
一言以蔽之:因为竞争条件。
考虑如下情况:若干($\ge2$)进程都在等待同一个缓冲块,构成了等待同一资源的进程等待队列。在缓冲块(资源)同步完毕后,会陆续唤醒各等待进程收取资源。陆续唤醒、轮到某一进程时,可能此时缓冲块已被刚刚被唤醒的前一进程重新占用,甚至加上了锁。因此进程被唤醒后需要重新检查资源是否可用,才能保证程序的正确性。
代码参考:
1 | // 代码路径:fs/buffer.c |
49. 操作系统如何利用 b_uptodate 保证缓冲块数据的正确性? new_block(int dev) 函数新申请一个缓冲块后,并没有读盘,b_uptodate 却被置 1,是否会引起数据混乱?详细分析理由。
b_uptodate 是缓冲块管理结构中的标志位,它的作用是告诉内核「缓冲块中的数据是否是最新的」。
当从硬盘读取已有文件时,b_uptodate 意味着硬盘上的数据是否已经同步到缓冲块中。置 1 时,说明缓冲块中的数据已完成同步,内核可以放心地支持进程与缓冲块进行数据交互;如果 b_uptodate 为 0,就提醒内核最新的数据还没有同步到该缓冲块上,向该缓冲块写入会导致竞争,因此也不支持进程共享该缓冲块。
为新建文件(或为文件添加的新数据)创建一个缓冲块时,b_uptodate 被置 1,这是因为此时的新文件刚刚由用户建立,本身就是最新的,硬盘上的内容才是“垃圾数据”、是落后的一方。因此,缓冲块中的 b_uptodate 被置为 1,不会引起混乱,而是读写逻辑需求导致。
严格来说,新建的数据块还可能用于存储文件的
i_zone间接块管理信息。如果是间接块管理信息,缓冲区必须清零,表示没有索引间接数据块,否则垃圾数据会导致索引错误,破坏文件操作的正确性。虽然缓冲块与硬盘数据块的数据不一致,但缓冲块上是更加新的数据,将
b_uptodate置1同样不会有问题。综上所述,设计者采用的策略如下:只要为新建的数据块新申请了缓冲块,不论该缓冲块将来用作什么,由于进程不需要里面原有的数据,干脆全部清零。这样不管与之绑定的数据块用来存储什么信息,都无所谓,同时将该缓冲块的
b_uptodate字段设置为1,更新问题“等效于”已解决。
50. add_request() 函数中有下列代码,其中的前两行(不含括号)是什么意思?
1 | // 代码路径:kernel/blk_drv/ll_rw_blk.c/add_request(...) |
前两行为:
1 | if (!(tmp = dev->current_request)) |
这两行查看指定设备是否有当前请求项,即查看设备是否忙。如果指定设备 dev 当前请求项 dev->current_request 为空,则表示目前设备没有请求项。本次是头一个请求项,也是当前唯一的一个请求项。因此:
- 可将「块设备当前请求指针」直接指向该请求项,
- 需要手动触发「相应设备的请求函数」——这一函数在请求队列非空时循环执行,但请求队列清空后便停止执行。因此放入新请求项时需要再次手动触发。
51. do_hd_request() 函数中 dev 的含义始终一样吗?
不一样。 do_hd_request() 函数主要用于处理当前硬盘请求项,但其中的 dev 变量含义并不一致。dev = MINOR(CURRENT->dev) 意味着取硬盘的逻辑设备号,对硬盘来说,为「物理硬盘号x5+硬盘上的分区号」。dev/=5 这一指令后表示的实际的物理设备号,即「第几块物理硬盘」。
1 | //代码路径:kernel/blk_drv/hd.c |
为什么会有这样复杂的设备号约定呢?Linux 0.11 中,设备号分为主设备号和次设备号。其中,硬盘的主设备号是 3。其它设备的主设备号分别为:
1-内存,2-磁盘, 3-硬盘, 4-ttyx, 5-tty,6-并行口,7-非命名管道
由于 1 个硬盘中可以存在 1-4 个分区,因此硬盘还依据分区的不同用次设备号进行指定分区。因此,硬盘的逻辑设备号由以下方式构成:
设备号=主设备号*256 + 次设备号
以两个硬盘、每个硬盘上有四个分区为例,具体的硬盘号如下表所示:
| 逻辑设备号 | 对应设备文件 | 说明 |
|---|---|---|
0x300 |
/dev/hd0 |
代表整个第 1 个硬盘 |
0x301 |
/dev/hd1 |
表示第 1 个硬盘的第 1 个分区 |
0x302 |
/dev/hd2 |
表示第 1 个硬盘的第 2 个分区 |
0x303 |
/dev/hd3 |
表示第 1 个硬盘的第 3 个分区 |
0x304 |
/dev/hd4 |
表示第 1 个硬盘的第 4 个分区 |
0x305 |
/dev/hd5 |
代表整个第 2 个硬盘 |
0x306 |
/dev/hd6 |
表示第 2 个硬盘的第 1 个分区 |
0x307 |
/dev/hd7 |
表示第 2 个硬盘的第 2 个分区 |
0x308 |
/dev/hd8 |
表示第 2 个硬盘的第 3 个分区 |
0x309 |
/dev/hd9 |
表示第 2 个硬盘的第 4 个分区 |
从 linux 内核 0.95 版后已经不使用这种烦琐的命名方式,而是使用与现在相同的命名方法了。
52. read_intr() 函数中,下列代码是什么意思?为什么这样做?
1 | // 代码路径:kernel/blk_drv/hd.c/read_intr() |
read_intr() 是对磁盘发出读取请求后操作系统用于处理磁盘返回中断的函数。当读取扇区操作成功后,-—CURRENT->nr_sectors 递减请求项所需读取的扇区数值。若递减后不等于 0,表示本项请求还有扇区没读完,于是再次置中断调用函数指针 do_hd = &read_intr; 并直接返回,等待硬盘在读出下一扇区数据后发出中断并再次调用本函数。
53. bread() 函数代码中为什么要做第二次 if (bh->b_uptodate) 判断?
1 | // 代码路径:fs/buffer.c/bread(int dev, int block) |
bread() 函数的功能是向内核中的上层函数提供从块设备上读取数据块的函数接口,而内部则为数据块加了一层 RAM 上的缓冲区作为块数据的缓存。
bread() 会调用底层 ll_rw_block() 函数,产生读设备请求。然后等待指定数据块读入,并等待缓冲块解锁。在睡眠醒来之后,如果缓冲块已更新 if (bh->b_uptodate),则返回缓冲块指针。否则,表明读设备操作失败,于是释放该缓冲块返回 NULL。
第一次检查:从高速缓冲区中取出需要的缓冲块, 判断缓冲块数据是否已同步,已读取过(严格来说要求缓冲块中数据时最新的)则返回此块。如果该缓冲块数据无效(更新标志未置位——这往往意味着缓冲块中的数据还没有从磁盘中读取), 则向设备发送数据块读取请求。 第二次检查:等指定数据块被读入,并且缓冲区解锁,睡眠醒来之后,要重新判断缓冲块是否有效。在睡眠等待过程中,数据可能已经发生了改变,所以要第二次判断。
54. getblk() 函数中,两次调用 wait_on_buffer() 函数,两次的意思一样吗?
1 | // 代码路径:fs/buffer.c |
相同又不同。都是等待缓冲块解锁,这是相同之处。
第一次调用是无条件的,已找到一个比较合适的空闲缓冲块 (bh->b_count==0),但是此块可能是加锁的(往往是因为正在同步至硬盘),于是等待该缓冲块解锁。
第二次调用, 是针对此块中原先的数据已被修改过(”脏的“)但尚未同步的情况,于是
- 先下达把数据同步到硬盘上的指令
sync_dev(bh->b_dev) - 同步时会加锁, 所以随后需要等待缓冲块解锁,即下一行的
wait_on_buffer(bh)。
值得注意的是,wait_on_buffer(bh) 时原则上可能有一整个缓冲队列(多个进程)在等待同一资源,因此等待结束后、当前进程调度前可能被其它进程抢先占据了资源,因此 Linus 又做了额外判断作为保险:
1 | if (bh->b_count) // 缓冲块又被其它某个进程先拿走了 |
当然,对缓冲块而言这种情况发生的频率应当是很低的。
55. getblk() 函数中,说明什么情况下执行 continue 、break。
1 | // 代码路径:fs/buffer.c/getblk(...) |
getblk() 函数主要是获取高速缓冲中的指定缓冲块。但缓冲块有可能正在被其它进程使用、有可能内容已修改需要写回,有可能正在写回,情况复杂。如何选取最合适的缓冲块,就成了这段代码要解决的问题。
缓冲块的参数指标有三个:
bh->b_count是缓冲块的引用计数,指明缓冲块被多少个进程使用。bh->b_dirt指明缓冲块的内容是否被修改过。如果被修改过后又要写入新内容,那原来的内容就需要先同步回磁盘。bh->b_lock是缓冲块的锁,指明缓冲块已被某个进程拥有且正在进行一些不可打断的原子操作。例如,某个进程正在同步缓冲块至磁盘时会给缓冲块加上锁。
free_list 是一个将所有缓冲块串在一起的双向链表。虽叫 “free” list,但实际上并不是包含所有空闲缓冲块的链表,而是一个大致表明缓冲块“空闲程度”的优先队列。每个缓冲块被使用过后会被挪移到链表的末尾,因此距离上次使用时间越长的缓冲块便会越接近链表的队头。因此这一链表逻辑上是一个优先队列,起到了类似 LRU 缓存策略的功能。
下面我们回到问题,作具体分析。
1 | // 代码路径:fs/buffer.c/getblk(...) |
get_hash_table(...)会试图找到已经被缓存的块并直接返回,若找不到则返回NULL。因此若代码运行至 1 处,说明在已有的缓冲区中找不到需要的内容,需要从硬盘中读取内容再返回。- 随后函数遍历
free_list寻找合适的缓冲块。由于是从前向后遍历,距上次使用时间更长的块更有可能被选中。若该缓冲块引用计数不为零,说明正在被其它进程使用;又因为「需要读取的内容」和「任意已有缓冲块中内容」都不一样,不可能使用该缓冲块。直接跳过,即运行continue。 - 若程序运行到 3 处,说明找到了一个不被其它进程使用的缓冲块,可以处理掉其中内容之后读取新内容。这样的缓冲块能用就行,但如果不脏就更好了。
- 若程序运行到 4 处,说明着找到了一个既没有被其它进程使用,也没有被修改过,也没有被加锁的缓冲块。这意味着找到了一个完美的空闲缓冲块,因此直接退出循环,即运行
break。
56. make_request() 函数 ,其中的 sleep_on(&wait_for_request) 是谁在等?等什么?
1 | // 代码路径:kernel/blk_drv/ll_rw_blk.c/make_request(...) |
这行代码等待的资源是空闲请求项,等待的进程是包括当前进程在内的所有需要这一资源的进程。
make_request() 函数主要功能为「创建请求项并将其插入请求队列」。执行 if 分支中的内容说明没有找到空请求项,即请求项数组 request[32] 中没有一项是空闲的。因此让进程暂停,等待前面的读写任务完成,等待请求项释放。
严格来说,是没有满足条件的请求项,因为读写操作的可用请求项部分不完全一样,写操作能够占用的请求项只有前
32*2/3=21个。如果是预读取请求(即
rw_ahead),那么在这种情况下便直接放弃。
57. 操作系统如何处理多个进程等待同一个正在与硬盘交互的缓冲块?
对于一个正在与硬盘交互的缓冲块,操作系统将其加锁。进程遇到加锁的缓冲块,需要执行 wait_on_buffer。
1 | // 代码路径:fs/buffer.c |
在 wait_on_buffer 中,如果缓冲块加锁,进程需要执行 sleep_on 函数。sleep_on 函数中,先将当前进程记录到 p=&bh->b_wait 中,供日后唤醒。然后将当前进程挂起、设置为不可打断的等待状态,最后调用 schedule() 切换至其它进程执行,直到当前进程被唤醒。
1 | // 代码路径:kernel/sched.c |
然而,一种更复杂的情况是多个进程等待同一个资源,例如,多个进程同时等待某个正在与硬盘交互的缓冲块。这时,当进程试图睡眠时 bh->b_wait 已经是一个非空值,里面保存着之前已经在等待的进程。为此,sleep_on 会先将 p=&bh->b_wait 中的内容暂存到 tmp 中,当自己被唤醒后再唤醒 tmp 中指向的进程。这样一来,所有等待同一资源的进程都会被唤醒。
1 | // 代码路径:kernel/sched.c |
某一时刻,多个等待某资源的进程的 sleep_on 函数中可能有多个 tmp 变量,依次指向这条“等待链”中的下一个进程。这时,函数中的临时指针 tmp 其实构成了一个隐式的等待队列,由该资源的 wait 指针(对缓冲块而言,是缓冲头中的 bh->b_wait)指向队列的队头(见下图)。唤醒时,由队头向后依次唤醒等待队列中的所有进程(见代码)。
![多个进程等待同一资源时形成的隐式队列[3]](/2022/12/31/Linux-0-11-%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E4%B8%8E%E6%80%9D%E8%80%83%E9%A2%98/wait_list.png)
58. add_request() 函数中有下列代码
1 | // 代码路径:kernel/blk_drv/ll_rw_blk.c/add_request(...) |
其中的
1 | if (!(tmp = dev->current_request)) { |
是什么意思?
查看指定设备是否有当前请求项,即查看设备是否忙。如果指定设备当前请求项为空,则表示目前设备没有请求项 (dev->current_request ==NULL),本次是第一个请求项,也是唯一的一个。因此可将块设备当前请求指针直接指向该请求项,并立即执行相应设备的请求函数。
59. 操作系统如何利用 buffer_head 中的 b_data, b_blocknr, b_dev, b_uptodate, b_dirt, b_count, b_lock, b_wait 字段管理缓冲块的?
管理缓冲块的「缓冲块头结构」struct buffer_head 在源代码中的定义如下:
1 | // 代码路径:include/linux/fs.h |
「缓冲块头结构」buffer_head 负责管理缓冲块以及进程与缓冲块的交互。
b_data 指向被管理的缓冲块数据。
b_dev,b_blocknr 是缓冲块中缓冲的数据(若有)的设备号(例如,硬盘的某个分区)和逻辑块号。
内核在 hash_table 表中搜索带有某内容的缓冲块时,只看设备号与块号(即 b_dev 和 b_blocknr)。只要缓冲块与硬盘数据的绑定关系还在,就认定数据块仍停留在缓冲块中,就可以直接返回、使用。
b_uptodate 与 b_dirt,是为了解决缓冲块的数据同步性而引入的两个标志。
b_uptodate 指明缓冲块中的内容是否是最新的。如果 b_uptodate 为 1,说明缓冲块的数据已经是数据块中最新的,可以支持进程共享缓冲块中的数据;如果 b_uptodate 为 0,提醒内核缓冲块并没有用绑定的数据块中的数据更新,不支持进程共享该缓冲块。当一个缓冲块中未载入硬盘上的数据时,缓冲块的 b_uptodate 为 0;当进程修改了某些内容而未同步入缓冲块中时, b_uptodate 也会置零。
b_dirt 是标记缓冲块中的内容是否被进程修改过了(“脏位”)。为 1 说明缓冲块的内容被进程方向的改写了,最终需要同步到硬盘上;b_dirt 为 0 则说明不需要同步。
b_count 记录每个缓冲块有多少进程共享,即引用计数。b_count 大于 0 表明有进程在共享该缓冲块;当进程不需要共享缓冲块时,内核会解除该进程与缓冲块的关系,并将 b_count 数值减 1,为 0 表明可以被当作新缓冲块来申请使用。
b_lock 为缓冲块的“加锁”标记。具体来说,为 1 说明缓冲块正与硬盘交互,内核会拦截进程对此时该缓冲块的操作,以免发生错误。交互完成后,置0,表明进程可以操作该缓冲块。
b_wait 记录等待缓冲块的解锁而被挂起的进程,指向等待队列的第一个进程的 task_struct。
60. 用图表示下面的几种情况,并从代码中找到证据:
- (a) 当进程获得第一个缓冲块的时候,哈希表
hash_table的状态。 - (b) 经过一段时间的运行,已经有 2000 多个
buffer_head挂到hash_table上时,hash 表(包括所有的buffer_head)的整体运行状态。 - (c) 经过一段时间的运行,有的缓冲块已经不被进程使用了(空闲),这样的空闲缓冲块是否会从
hash_table上脱钩? - (d) 经过一段时间的运行,所有的
buffer_head都挂到hash_table上了,这时,又有进程申请空闲缓冲块,将会发生什么?
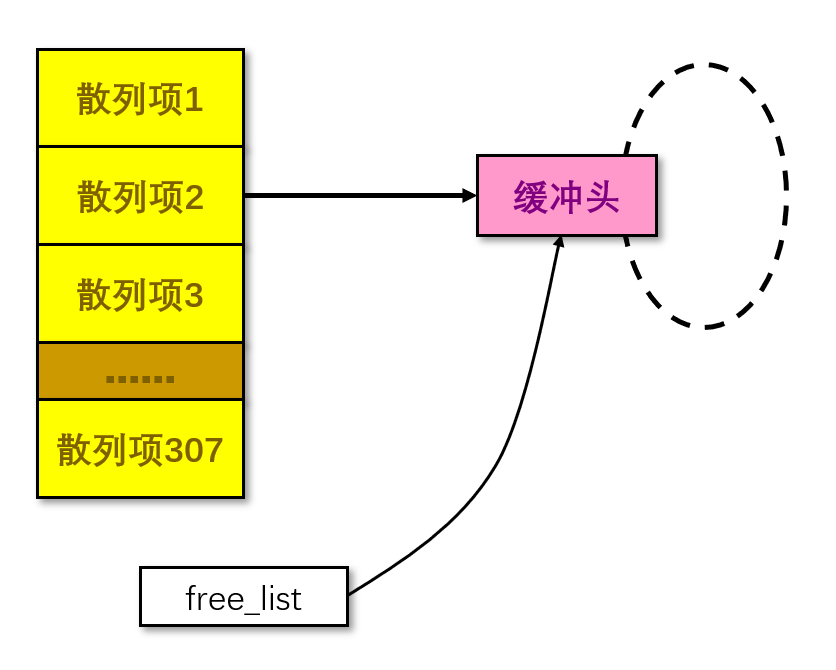
(a) Linux-0.11 中,采用了两种管理缓冲块的数据结构:一个哈希表 hash_table[307],用于根据设备号和块号快速找到需要的缓冲块(如果有的话);和一个实现为双向链环的优先队列 free_list,用于按序存储 least recently used 的缓冲块。代码证据如下所示:
1 | // 代码路径:fs/buffer.c |
假设第一个缓冲块挂在了 hash_table[1] 上,此时哈希表的状态如下图所示:
(b) 运行一段时间、有很多缓冲块被挂在哈希表上时,整体的运行状态大致如下图所示:
![许多缓冲块时的数据结构[3]](/2022/12/31/Linux-0-11-%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E4%B8%8E%E6%80%9D%E8%80%83%E9%A2%98/hash_table_b.png)
(c) 不会。缓冲区的设计原则是让缓冲块尽可能久地停留在内存中,从而便于随后重用、减少访存时间。即使一个缓冲块的引用计数减至零,也不会被直接从哈希表上拿走,而是留在内存中,直到重新被引用,或者为了缓冲其它内容而被覆盖。
(d) 为了获取新的、可用的缓冲块,内核沿 free_list 依次遍历查找 least recently used 的缓冲块:
- 引用计数为零(
b_count==0)且不需要同步操作的缓冲块最优先; - 引用计数为零且正在同步的(
b_lock==1)缓冲块次之; - 引用计数为零且需要同步(
b_dirt==0)但还没有开始同步的(b_lock==0)块再次; - 如果没有引用计数为零的缓冲块,说明所有缓冲块都被其它进程占用了。内核会挂起当前进程,等待空闲缓冲块。
Part IV 文件系统第一步:加载根文件系统
61. 在代码中多次出现一个宏 ROOT_DEV,即根设备。什么是根设备?与文件系统、根文件系统有什么关系?
操作系统中的文件系统大致可以分为两部分:一部分在操作系统内核中,另一部分在硬盘、软盘、虚拟盘中。每个逻辑盘(例如硬盘的分区、虚拟盘)中由索引节点(i节点,inode)和目录文件形成文件的树状结构,构成了每个逻辑盘中的文件系统。每个逻辑盘中的文件系统有一个根索引节点,由根索引节点便可找到文件系统中的所有文件。
硬盘可以有多个分区,每个分区中有自己单独的文件系统,因此操作系统可能要面对多个文件系统。然而 Unix 和 Linux 系统中最终呈现给用户的是一个单独的文件树,所有的设备、文件都被组织到了一棵单独的树上。这一矛盾是怎么解决的呢?为此,不同的文件系统需要相互挂载,一个文件系统的根索引节点会被挂载到另一文件系统的某个目录上。这样一来,被挂载的文件系统就好像是上层文件系统的一个目录一样。在 Linux 系统中,可以通过大家熟悉的 mount 指令实现文件系统之间的挂载。
当文件系统相互挂载,最上层的文件系统便被称为根文件系统。根文件系统的根节点成为了整个 Linux 文件树的根,而其它文件系统只是 Linux 文件树中的一个目录。进一步的,根文件系统所在的设备就叫根设备。
62. 在虚拟盘被设置为根设备之前,操作系统的根设备是软盘,请说明设置软盘为根设备的技术路线。
首先,将软盘的第一个扇区设置为可引导扇区:
1 | # 代码路径:boot/bootsect.s |
在主 Makefile 文件中设置 ROOT_DEV=/dev/hd6。并且在 bootsect.s 中的第 508 和 509 比特处设置ROOT_DEV=0x306;在 tools/build 中根据 Makefile 中的 ROOT_DEV 设置 MAJOR_TOOT 和 MINOR_ROOT,并将其填充在偏移量为 508 和 509 处:
1 | // 代码路径:Makefile |
随后被移至 0x90000+508=0x901FC 处,最终在 main.c 中设置为 ORIG_ROOT_DEV 并将其赋给 ROOT_DEV 变量:
1 | // 代码路径:init/main.c |
63. Linux-0.11 是怎么将根设备从软盘更换为虚拟盘,并加载了根文件系统?
操作系统自启动之后就在不断地挪移、覆盖 ROOT_DEV 变量的值,直到 mount_root 函数中才真正地根据该变量的值挂载根文件系统。
1 | // 代码路径:kernel/blk_drv/hd.c |
rd_load 函数首先从软盘读取虚拟盘的文件系统映像 (image) 并将其复制到虚拟盘中,随后设置 ROOT_DEV 为 0x0101 将根设备从软盘更换为虚拟盘。主设备号是1,代表内存,即将内存虚拟盘设置为根目录。
1 | // 代码路径:kernel/blk_drv/ramdisk.c |
随后,sys_setup 调用 mount_root 函数,真正地挂载根文件系统。过程如下:首先,初始化文件管理结构 file_table[64] 和超级块数据结构 super_block[8]。随后,读取根文件系统的超级块和根索引节点。然后,将超级块和根索引节点关联起来,并将根文件系统的根索引节点设置为1进程的当前工作目录和根目录。最后,统计空闲逻辑块数及空闲索引节点数,并打印显示给用户。
1 | // 代码路径:fs/super.c |
参考文献
[1] Linux kernel source code, by Linus Torvalds et al., version 0.11(0.95), 1991.
[2] 《Linux内核设计的艺术》,新设计团队(即杨力祥老师带领的团队^_^) 著,第2版,2013年出版.
[3] 《Linux内核完全注释 内核版本0.11(0.95)》,赵炯 著,修正版1.9.5,2004年.
[4] IA-32 Intel® Architecture Software Developer’s Manual, by Intel, 2003.
[5] 《IA-32 架构软件开发人员手册 第3卷:系统编程指南(中文版-部分)》,lijshu等 译,2005年.
[6] 为什么BIOS要将主引导扇区(MBR)加载到0x7c00这个地址?,by greatgeek,CSDN,https://blog.csdn.net/greatgeek/article/details/102542271,2019年.
[7] 知乎问题“在游戏的发展历史中,出现过哪些有意思的加密反盗版机制和破解机制?”下用户「Zign」的回答,by Zign,知乎,https://www.zhihu.com/question/46773069,2018年.
[8] OldLinux(赵炯博士创建的在线Linux分享讨论平台),www.oldlinux.org.
附录:思考题调整前后编号对照表
在修订时,为了让问题之间的逻辑更加连贯,我重新调整了思考题的顺序。为了方便与原版思考题题目对照参考、查找答案,我把原编号和现编号的对照关系放在这里。
| 现 → 原 | 1 → 1 | 2 → 2 | 3 → 3 |
|---|---|---|---|
| 4 → 4 | 5 → 5 | 6 → 6 | 7 → 41 |
| 8 → 7 | 9 → 44 | 10 → 40 | 11 → 8 |
| 12 → 9 | 13 → 10 | 14 → 11 | 15 → 42 |
| 16 → 12 | 17 → 61 | 18 → 43 | 19 → 13 |
| 20 → 14 | 21 → 62 | 22 → 15 | 23 → 17 |
| 24 → 16 | 25 → 46 | 26 → 53 | 27 → 18 |
| 28 → 47 | 29 → 48 | 30 → 19 | 31 → 49 |
| 32 → 56 | 33 → 20 | 34 → 21 | 35 → 50 |
| 36 → 22 | 37 → 23 | 38 → 45 | 39 → 24 |
| 40 → 29 | 41 → 51 | 42 → 52 | 43 → 25 |
| 44 → 54 | 45 → 26 | 46 → 27 | 47 → 28 |
| 48 → 30 | 49 → 31 | 50 → 32 | 51 → 33 |
| 52 → 34 | 53 → 35 | 54 → 36 | 55 → 37 |
| 56 → 38 | 57 → 63 | 58 → 60 | 59 → 55 |
| 60 → 57 | 61 → 原创 | 62 → 58 | 63 → 59 |
Linux-0.11 源码解析与思考题
http://icychlorine.github.io/2022/12/31/Linux-0-11-源码解析与思考题/